
Se lavorate nel mondo della data science, dell’analisi dei dati, del machine learning o dell’Intelligenza Artificiale, avrete probabilmente già incontrato il termine “pipeline”. Ma cosa significa esattamente costruire una pipeline robusta?
Beh, la risposta è più semplice e meno complessa di quanto pensiate. Una pipeline è una sequenza di operazioni che trasformano i dati da un punto A ad un punto B, spesso passando per molteplici stazioni intermedie. L’obiettivo finale? Avere dati puliti, strutturati e pronti per essere analizzati, modellati o visualizzati.
Cos’è una pipeline e perché è essenziale in Python
Immaginate di dover preparare una torta. Non prendereste tutti gli ingredienti, li lancereste in una ciotola a caso e sperereste nel meglio, giusto? Ci sono dei passaggi: setacciare la farina, mescolare le uova con lo zucchero, aggiungere gli ingredienti secchi a quelli umidi, e così via. Ogni passaggio è cruciale per il risultato finale. Una pipeline di dati funziona più o meno allo stesso modo.
In un mondo dove i dati sono diventati una fonte importantissima di informazioni ed insights, la capacità di gestirli in modo efficiente è fondamentale. I dati arrivano da fonti disparate, in formati diversi, spesso sporchi, incompleti o semplicemente… caotici. Una pipeline entra in gioco proprio qui, permettendoci di prendere questi dati grezzi e di raffinarli, purificarli e trasformarli in qualcosa di utilizzabile.
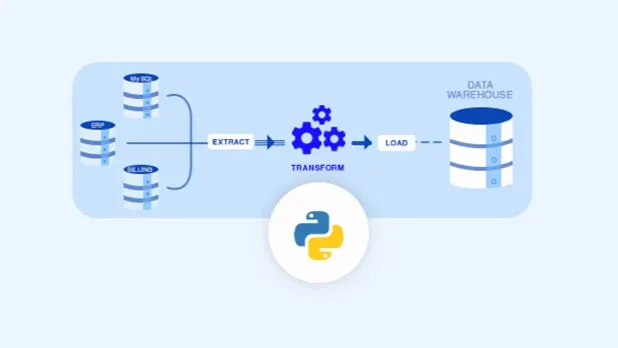
Perché Python è il linguaggio prediletto per questo tipo di operazioni? Semplice: la sua versatilità, la sua sintassi leggibile e l’enorme ecosistema di librerie lo rendono un candidato ideale. È come avere un coltellino svizzero potentissimo per ogni esigenza legata ai dati.
Come le pipeline semplificano il flusso di lavoro nei progetti Python
Senza una pipeline, ogni volta che doveste elaborare nuovi dati, sareste costretti a ripetere manualmente una serie infinita di passaggi. È un po’ come lavare i piatti a mano dopo ogni pasto, quando potreste avere una lavastoviglie. La lavastoviglie, in questo caso, è la nostra pipeline: automatizza un processo ripetitivo e ci libera del tempo prezioso per concentrarci su compiti più stimolanti e creativi.
Le pipeline garantiscono coerenza. Se il vostro processo di pulizia dei dati è racchiuso in una pipeline ben definita, siete sicuri che ogni nuovo set di dati subirà le stesse trasformazioni, riducendo drasticamente il rischio di errori umani. Provate a pulire manualmente 1000 file di testo, ognuno con piccole differenze: la probabilità di commettere un errore è altissima. Con una pipeline, una volta impostata la logica, questa verrà applicata in modo identico a tutti i file.
Inoltre, le pipeline migliorano la manutenibilità e la scalabilità. Se un giorno doveste modificare un passaggio specifico (magari perché è cambiata la struttura dei dati sorgente), vi basterà intervenire su un solo modulo della pipeline, senza dover riscrivere l’intero processo. E quando i volumi di dati aumentano, una pipeline ben progettata può essere scalata per gestire carichi maggiori senza troppi patemi d’animo, un aspetto fondamentale per chiunque lavori con grandi moli di informazioni.
Insomma, una pipeline è una struttura organizzata che ci permette di prendere i dati grezzi e di portarli, attraverso una serie di trasformazioni logiche e sequenziali, al punto in cui sono pronti per essere utilizzati. È il segreto per trasformare il caos dei dati in un’orchestra armoniosa di informazioni utili. E se non sapete da dove iniziare, c’è sempre un corso Python per iniziare.
I passi fondamentali per costruire una pipeline robusta in Python
Costruire una pipeline non è un’arte oscura riservata a pochi eletti. Con un po’ di metodo e le giuste conoscenze, chiunque può farlo. Certo, non è come montare un mobile IKEA (anche se a volte può sembrare altrettanto frustrante), ma seguendo alcuni passi fondamentali, il percorso sarà meno tortuoso.
Il primo passo, e forse il più cruciale, è la comprensione del problema. Prima di scrivere una singola riga di codice, dobbiamo sapere esattamente cosa vogliamo ottenere dalla nostra pipeline. Quali sono i dati in ingresso? Qual è il formato desiderato per l’output? Quali trasformazioni devono subire i dati? Senza una chiara definizione degli obiettivi, rischiamo di costruire una splendida autostrada… che non porta da nessuna parte.
Una volta definiti gli obiettivi, si passa alla fase di raccolta dati. I dati possono provenire da database, API, file CSV o fogli Excel. La sfida qui è spesso l’eterogeneità delle fonti e la necessità di estrarre i dati in un formato che sia il più uniforme possibile. Qui Python, con la sua miriade di librerie per la connessione a database, la lettura di file e l’interazione con API, si rivela un alleato insostituibile.
Successivamente, c’è la fase di pulizia e pre-elaborazione dei dati. In questa fase, ci occupiamo di gestire i valori mancanti, correggere gli errori di formato, rimuovere i duplicati, normalizzare i dati e, in generale, rendere i dati presentabili. È qui che si separano i dati buoni da quelli “boh, forse sono buoni”. Per chi è alle prime armi, ci sono sempre i nostri consigli per iniziare a studiare Python che possono aiutare a superare le prime difficoltà.
Infine, c’è la fase di trasformazione e caricamento. Una volta puliti, i dati vengono trasformati nel formato finale desiderato. Questo potrebbe significare aggregare i dati, calcolare nuove feature, o applicare modelli di machine learning. Dopo queste trasformazioni, i dati vengono caricati nella destinazione finale, che può essere un altro database, un data warehouse, un file per l’analisi, o un’applicazione.
Creazione e gestione di flussi di dati con Python
Quando parliamo di flussi di dati, intendiamo il movimento e l’elaborazione continua delle informazioni. In Python, ci sono diversi modi per orchestrare questi flussi. Uno degli approcci più comuni è l’utilizzo di script sequenziali, dove ogni script esegue una parte della pipeline e passa il risultato al successivo. È un inizio, ma può diventare ingombrante e difficile da gestire man mano che la pipeline cresce.
Per flussi più complessi e robusti, si tende ad utilizzare dei framework di orchestrazione. Questi framework ci permettono di definire le dipendenze tra le diverse fasi, di gestire gli errori, di schedulare l’esecuzione della pipeline e di monitorarne lo stato.
Un concetto chiave nella gestione dei flussi è l’idempotenza. Un’operazione è idempotente se può essere eseguita più volte senza cambiare il risultato finale dopo la prima esecuzione. Questo è cruciale in una pipeline: se un passaggio fallisce e deve essere rieseguito, non vogliamo che crei duplicati o corrompa i dati già elaborati. È un po’ come premere il pulsante “salva” più volte in un documento: il documento rimane salvato una sola volta, ma ci assicura che il lavoro non vada perso.
Un altro aspetto fondamentale è la gestione degli errori. Le cose vanno storte, è inevitabile. Un file non viene trovato, una connessione al database fallisce, un’API restituisce un errore inaspettato. Una pipeline robusta deve essere in grado di gestire queste eccezioni in modo elegante, registrando gli errori, notificando gli interessati e, se possibile, tentando di recuperare. Non vogliamo che l’intera catena di montaggio si fermi per un bullone allentato.
Strumenti e librerie Python per costruire pipeline efficienti
Python è un vero e proprio parco giochi per chi vuole costruire pipeline. L’ecosistema è vastissimo e offre soluzioni per ogni esigenza.
Per la manipolazione e l’analisi dei dati, non si può non menzionare Pandas. Questa libreria è fondamentale per la gestione dei dati tabellari. Con i suoi DataFrame, potete caricare, pulire, trasformare e analizzare dati con una facilità disarmante. È come avere un foglio Excel superpotenziato, ma con la flessibilità e la programmabilità di Python. Se avete a che fare con CSV, Excel, SQL o JSON, Pandas sarà il vostro migliore amico.
Quando si parla di operazioni numeriche e scientifiche, entra in gioco Numpy. È la base di molte librerie scientifiche in Python e offre strutture dati efficienti (array multidimensionali) e funzioni per operazioni matematiche complesse. È il motore silenzioso che alimenta molte delle vostre analisi.
Per le pipeline di machine learning, Scikit-learn è la libreria di riferimento. Offre una vasta gamma di algoritmi di classificazione, regressione, clustering e riduzione della dimensionalità, oltre a strumenti per la pre-elaborazione dei dati e la valutazione dei modelli.
Per l’orchestrazione delle pipeline, ci sono strumenti più specifici. Apache Airflow è probabilmente il più popolare. Permette di definire le pipeline come Directed Acyclic Graphs (DAGs), offrendo un’interfaccia web per monitorare e gestire i flussi. È potente, flessibile e ampiamente utilizzato nel settore. Altri strumenti includono Prefect e Luigi, ognuno con le sue peculiarità e punti di forza. La scelta dipende spesso dalla complessità della pipeline e dalle esigenze specifiche del progetto.
Per la gestione degli ambienti virtuali, venv o Conda sono essenziali. Permettono di isolare le dipendenze dei progetti, evitando conflitti tra librerie e versioni. Praticamente avete una stanza separata per ogni progetto, dove ogni cosa è al suo posto e non c’è rischio che le librerie di un progetto interferiscano con quelle di un altro.
Best practices nello sviluppo di librerie Python
Sviluppare una pipeline robusta non significa solo scegliere gli strumenti giusti, ma anche seguire alcune “regole del buon vicinato” in fatto di codice.
Prima di tutto, la modularità. Dividete la vostra pipeline in funzioni e moduli più piccoli e riutilizzabili. Ogni funzione dovrebbe fare una sola cosa e farla bene. Questo rende il codice più leggibile, più facile da testare e più semplice da mantenere.
Non stancatevi mai di testare ogni singola parte della vostra pipeline. I test unitari, i test di integrazione e i test end-to-end sono fondamentali per garantire che ogni componente funzioni come previsto e che l’intera pipeline si comporti correttamente. Un bug in una fase iniziale può avere effetti a cascata disastrosi.
La documentazione è un’altra best practice spesso sottovalutata. Documentate il vostro codice, spiegate cosa fa ogni funzione, quali sono gli input attesi e gli output prodotti. Anche se pensate di ricordarvi tutto, un giorno vi ringrazierete.
Infine, la gestione delle versioni con strumenti come Git è imprescindibile. Permette di tenere traccia di tutte le modifiche, di collaborare con altri sviluppatori e di tornare indietro a versioni precedenti se qualcosa va storto. È il vostro “annulla” superpotenziato per l’intero progetto.
Seguendo queste linee guida, la vostra pipeline non sarà solo funzionale, ma anche un piacere da mantenere e sviluppare.
Come diventare esperti nello sviluppo in Python: i consigli di Data Masters
Arrivati a questo punto, potreste sentirvi un po’ come un apprendista stregone di fronte a un calderone ribollente. Le pipeline, con tutte le loro complessità, possono sembrare un Everest da scalare. Ma non temete! Con la giusta guida e un pizzico di determinazione, potete trasformarvi da principianti a veri e propri maestri del codice.
Il primo consiglio, e forse il più ovvio, è studiare. Non c’è scorciatoia per la conoscenza. Fortunatamente, le risorse per imparare Python sono infinite, adi tutorial online, ai libri, ai corsi strutturati, c’è un percorso per ogni tipo di apprendimento. Se il vostro obiettivo è diventare un professionista del settore, un percorso formativo per diventare Python Developer può essere la scelta giusta, offrendo una panoramica completa e approfondita.
Leggere libri e guardare video è un ottimo inizio, ma la vera comprensione arriva solo quando mettete le mani in pasta. Scrivete codice, risolvete problemi, implementate piccoli progetti. Non abbiate paura di fare errori, sono i vostri migliori insegnanti. È un po’ come imparare a nuotare: potete leggere tutti i manuali che volete, ma finché non vi tuffate in acqua, non imparerete mai veramente.
Non abbiate paura di sporcarvi le mani con progetti reali. Non devono essere progetti giganteschi e complessi. Iniziate con qualcosa di piccolo: automatizzate un compito ripetitivo nella vostra vita quotidiana, analizzate un dataset pubblico che vi interessa, create una piccola web app. Questi progetti vi daranno esperienza pratica e vi aiuteranno a consolidare le vostre conoscenze.
Partecipate alle community, il mondo di Python è vasto e accogliente. Ci sono forum, gruppi di discussione, conferenze e meetup locali. Interagire con altri sviluppatori, porre domande, condividere le vostre esperienze e imparare dagli altri è un modo fantastico per crescere. Spesso, la soluzione a un problema che vi sta tormentando da ore può arrivare da un consiglio di chi ha già affrontato una situazione simile.
E non dimenticate di rimanere aggiornati. Il mondo della tecnologia si evolve a una velocità vertiginosa, nuove librerie, nuovi framework, nuove best practice emergono costantemente. Dedicate del tempo a leggere blog, seguire conferenze, sperimentare nuove tecnologie. Il nostro percorso è progettato per tenervi al passo con le ultime novità.
Costruire una pipeline robusta con Python è un’abilità preziosa che vi aprirà molte porte nel mondo dei dati. Richiede impegno, studio e tanta pratica, ma la soddisfazione di vedere i vostri dati fluire senza intoppi, trasformandosi in informazioni utili, è impagabile. Quindi, rimboccatevi le maniche, aprite il vostro editor di codice preferito e iniziate a costruire il vostro capolavoro di dati!

AUTORE:Simone Truglia Apri profilo LinkedIn
Simone è un Ingegnere Informatico con specializzazione nei sistemi automatici e con una grande passione per la matematica, la programmazione e l’intelligenza artificiale. Ha lavorato con diverse aziende europee, aiutandole ad acquisire e ad estrarre il massimo valore dai principali dati a loro disposizione.











