
Il premio Nobel per la fisica del 2024 è stato assegnato a John Hopfield e Geoffrey Hinton “per scoperte e invenzioni fondazionali che abilitano l’apprendimento automatico nelle reti neurali artificiali”, come dice il comunicato ufficiale.
L’annuncio continua, dicendo che Hinton “ha inventato un metodo in grado di scoprire […] proprietà nei dati e che è diventato importante per le grandi reti neurali artificiali oggi in uso”.
La scoperta alla base del Premio Nobel è la cosiddetta backpropagation, un algoritmo che permette alle reti neurali di apprendere dagli errori commessi durante il processo di previsione. Questo metodo rivoluzionario, introdotto da Hinton assieme a David E. Rumelhart e R. J. Williams verso la fine del 1986, ha consentito di allenare modelli matematici complessi, rendendoli in grado di migliorarsi continuamente, in una maniera che ricorda da vicino il metodo che gli esseri umani hanno per apprendere.
L’articolo pubblicato su Nature nell’ottobre di quell’anno ha il nome “Learning representations by back-propagating errors”, vale a dire “Imparare le rappresentazioni tramite la propagazione all’indietro degli errori”.
L’articolo rappresentava un punto di svolta per la ricerca nel campo dell’intelligenza artificiale. Prima dell’introduzione della backpropagation, le reti neurali erano limitate dalla loro incapacità di gestire complessi insiemi di dati. Il metodo della backpropagation, invece, permette di distribuire e correggere gli errori lungo tutti i livelli della rete, affinando così le capacità del modello di riconoscere schemi nascosti nei dati e migliorare le previsioni in modo iterativo e progressivo.

Come funziona la backpropagation?
La backpropagation è parte integrante di un metodo di ottimizzazione più generale chiamato discesa del gradiente. Esso è un algoritmo di ottimizzazione che esisteva da ben prima del 1986 e che viene tuttora utilizzato per minimizzare l’errore in un modello matematico il cui compito è fare predizioni basandosi su dati.
L’idea è semplice: dopo aver fatto una previsione, il modello calcola quanto ha sbagliato (cioè l’errore) e usa questa informazione per aggiornare i propri parametri in modo da ridurre l’errore nelle previsioni future.
La backpropagation, introdotta da Geoffrey Hinton insieme a David E. Rumelhart e Ronald J. Williams negli anni ’80, ha permesso di applicare efficacemente la discesa del gradiente alle reti neurali multilivello, quelle che oggi chiamiamo reti neurali profonde (deep neural networks). Prima di questa scoperta, addestrare modelli complessi con più strati era estremamente difficile, perché non c’era un modo efficiente per aggiornare i pesi di ciascun nodo nella rete. La backpropagation ha risolto questo problema permettendo di “propagare” l’errore dal livello finale della rete (dove si ottiene la previsione) fino ai livelli precedenti, aggiornando i pesi lungo tutto il percorso.
Nei meandri della backpropagation
Cerchiamo di capire meglio come funziona: immaginiamo di avere un modello matematico (oppure se preferiamo un modello di machine learning) che cerca di prevedere il prezzo di una casa basandosi su fattori come la superficie, il numero di stanze e la posizione.
Prima di poter essere usati nel mondo reale, questi modelli devono addestrarsi, ovvero studiare i dati su cui baseranno le proprie predizioni. All’inizio del suo processo di addestramento, il modello fa una previsione per una casa specifica, ammettiamo che stimi un prezzo di 200.000 euro. Ma -hey- viene fuori che il prezzo reale della casa è 250.000 euro. Il modello ha sbagliato. Cosa succede adesso?
Entra in gioco la backpropagation.
Come funziona?
- Fase di previsione (forward pass): Il modello prende i dati della casa (superficie, stanze, posizione) e produce una stima iniziale del prezzo. In questo caso, la previsione è di 200.000 euro.
- Calcolo dell’errore: Il modello confronta la sua previsione con il prezzo reale (250.000 euro). L’errore viene calcolato come la differenza tra la previsione e il valore corretto: in questo esempio, l’errore è di 50.000 euro (250.000 – 200.000).
- Propagazione dell’errore (backpropagation): L’errore viene “propagato all’indietro” attraverso il modello. Il modello va a rivedere il contributo di ciascuno dei fattori usati per fare la previsione (superficie, stanze, posizione) e cerca di capire quale di questi fattori ha influenzato di più l’errore. Ad esempio, potrebbe rendersi conto che ha sottovalutato l’importanza della posizione.
- Aggiornamento dei parametri: Una volta identificato quali fattori hanno causato l’errore, il modello corregge i “pesi” che aveva assegnato a ciascun fattore. Ad esempio, potrebbe aumentare il peso assegnato alla posizione (se questa era più importante del previsto per il prezzo finale) e diminuire quello della superficie (se era stato considerato troppo rilevante).
- Ripetizione: Dopo questa correzione, il modello viene esposto ad altri dati (altre case), continua a fare previsioni, confronta l’errore e si corregge di nuovo. A ogni ciclo, il modello diventa sempre più accurato nel prevedere il prezzo delle case.
Per capire ancora meglio cosa succede durante l’addestramento di un modello osserviamo l’immagine qui sotto, che mostra visivamente il funzionamento di questo algoritmo di ottimizzazione:
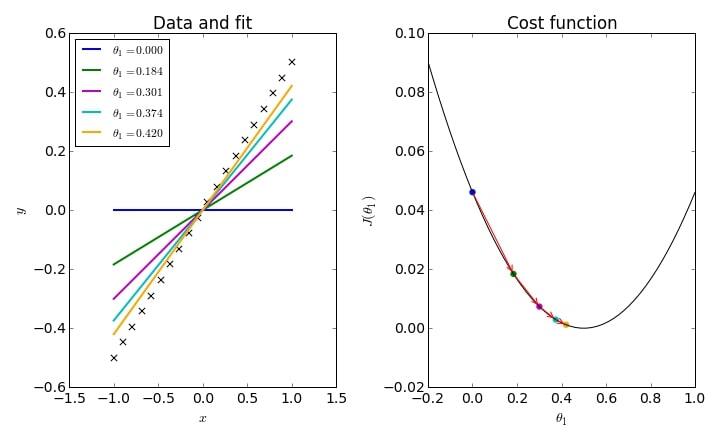
A sinistra, vediamo come il modello tenta di adattarsi ai dati, variando il parametro θ1 (la pendenza della retta) per migliorare la sua previsione. All’inizio, i tentativi del modello possono essere piuttosto imprecisi (vedi la retta blu o quella verde), ma man mano che apprende dagli errori, il modello migliora, avvicinandosi alla retta arancione, che rappresenta la migliore previsione possibile.
A destra, vediamo la funzione di costo J(θ1), che ci indica quanto il modello sta sbagliando. La backpropagation consente al modello di “scendere” lungo questa curva, riducendo l’errore passo dopo passo fino a trovare il punto minimo, dove l’errore è più basso (corrispondente alla retta arancione nell’immagine di sinistra).
Questo processo di riduzione dell’errore attraverso iterazioni successive è alla base del funzionamento di modelli complessi come quelli che usiamo oggi per predire prezzi o riconoscere immagini.
Dopo questa spiegazione appare chiaro come già da tempo la strada alle reti neurali fosse aperta, ma il vero elemento che ha reso possibile il loro enorme sviluppo è stata la disponibilità di dati. Le reti neurali e più in generale i modelli di machine learning, grazie alla backpropagation, imparano esclusivamente dai dati che gli vengono forniti. Più dati hanno a disposizione, più possono apprendere e diventare accurate.
Backpropagation: 40 anni e non sentirli
L’invenzione di Hinton, che all’epoca sembrava una scoperta di nicchia nel mondo accademico, è oggi alla base di tecnologie che utilizziamo ogni giorno, spesso senza rendercene conto. Grazie a questa tecnica, modelli matematici possono analizzare enormi quantità di dati e apprendere da essi in modi che prima erano inimmaginabili. Il riconoscimento vocale di Alexa, la visione artificiale che permette alle auto a guida autonoma di “vedere” e navigare nel traffico, o ancora gli algoritmi di raccomandazione che ci suggeriscono film su Netflix o acquisti su Amazon, esistono perché la backpropagation ha permesso ai modelli di “imparare” e migliorare costantemente le loro previsioni.
Tutto questo non sarebbe stato possibile senza la backpropagation. È evidente come l’impatto dell’opera di Geoffrey Hinton vada ben oltre la teoria. La sua invenzione ha tracciato la strada dell’era contemporanea, in cui l’intelligenza artificiale è parte integrante della nostra vita quotidiana in ogni campo: intrattenimento, sanità, mobilità, lavoro. Il contributo di Hinton ha permesso di fatto la rivoluzione industriale dell’intelligenza artificiale che stiamo vivendo ora, a quasi 40 anni dalla sua invenzione più famosa.
Il Premio Nobel del 2024 riconosce non solo il valore di una singola invenzione, ma l’impatto (destinato a durare) che questa ha avuto – e avrà ancora – nelle vite degli esseri umani.

AUTORE:Giuseppe Mastrandrea Apri profilo LinkedIn
Giuseppe è un Ingegnere Informatico con una forte specializzazione e pubblicazioni in ambito Computer Vision. Da circa 8 anni si dedica all’insegnamento in ambito informatico e alla formazione sulle tecnologie emergenti tra le quali il Machine Learning.











