
Nel vasto universo dell’Intelligenza Artificiale, la scelta di un algoritmo di ottimizzazione efficiente è cruciale per il successo dei progetti.
Adam è un algoritmo di ottimizzazione che ha rivoluzionato questo campo. Il suo nome deriva da “adaptive moment estimation” e può essere utilizzato come un’alternativa alla discesa del gradiente per aggiornare iterativamente i pesi della rete neurale in base ai dati di addestramento.
Adam è molto popolare nel campo del Deep Learning, principalmente per la sua capacità di raggiungere rapidamente risultati di alta qualità.
Ecco alcuni dei suoi punti di forza:
- Facilità di implementazione;
- Efficienza computazionale;
- Basso utilizzo della memoria;
- Invarianza al ridimensionamento diagonale dei gradienti;
- Adattabilità a problemi di grandi dimensioni in termini di dati e/o parametri;
- Adattabilità a obiettivi non stazionari;
- Efficacia in problemi con gradienti molto rumorosi o scarsi;
- Gli iperparametri hanno un’interpretazione intuitiva e, in generale, richiedono poca messa a punto.
Come funziona?
La peculiarità di Adam risiede nella sua capacità di adattare i tassi di apprendimento per ciascun peso della rete, diversamente dalla discesa del gradiente, che mantiene un unico tasso di apprendimento per tutti gli aggiornamenti del peso. Questa adattabilità si traduce in prestazioni notevolmente migliori nei problemi con gradienti molto rumorosi o scarsi.
Adam combina i vantaggi di due popolari algoritmi di ottimizzazione, AdaGrad e RMSProp. AdaGrad mantiene un tasso di apprendimento per parametro che migliora le prestazioni su problemi con gradienti sparsi, come quelli riscontrati nel Natural Language Processing (NLP) e nella Computer Vision. RMSProp, d’altra parte, mantiene i tassi di apprendimento per parametro che vengono adattati in base alla media delle recenti grandezze dei gradienti per il peso
Più specificamente, Adam calcola una media mobile esponenziale del gradiente e del gradiente al quadrato, e i parametri beta1 e beta2 sono utilizzati per controllare i tassi di decadimento di queste medie mobili. Questo approccio consente di superare la distorsione iniziale delle stime del momento verso lo zero, garantendo prestazioni ottimali durante tutto il processo di addestramento.
È importante sottolineare le prestazioni di Adam rispetto ad altri algoritmi di ottimizzazione.
In numerosi test, Adam ha dimostrato di fornire risultati superiori, superando di gran lunga altri algoritmi per una migliore ottimizzazione del gradiente. Ad esempio, in uno studio comparativo sull’addestramento di una rete neurale multistrato sulle immagini MNIST, Adam ha superato altri ottimizzatori come SGD, RMSprop e Adagrad1.
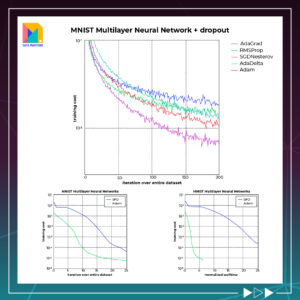
Tuttavia, nonostante le sue ottime prestazioni, Adam non è privo di limitazioni. Per esempio, l’ottimizzatore LAMB, che è una variante di Adam, è stato trovato per offrire prestazioni superiori su grandi batch di dati. LAMB mantiene i vantaggi di Adam, ma modifica il modo in cui vengono calcolati i tassi di apprendimento per gestire meglio i grandi batch di dati. Questo rende LAMB una scelta preferibile quando si lavora con enormi set di dati, dove la dimensione del batch cresce linearmente.
Inoltre, è stato introdotto un altro ottimizzatore chiamato AdaBound, che cerca di combinare i punti di forza di Adam e SGD. AdaBound utilizza l’adattamento dinamico dei tassi di apprendimento, simile a Adam, ma aggiunge un limite superiore che previene la crescita illimitata del tasso di apprendimento, come in SGD. Ciò può portare a migliori prestazioni in alcuni scenari, fornendo un altro strumento per il toolkit di un esperto di deep learning.
Nel complesso, pur con queste potenziali limitazioni e alternative, Adam rimane un algoritmo di ottimizzazione altamente efficace e popolare, ampiamente utilizzato in una varietà di applicazioni di Deep Learning grazie alla sua combinazione di efficienza, facilità di utilizzo e prestazioni.
Parametri di configurazione
alfa: chiamato anche learning rate, tasso di apprendimento o dimensione del passo. Indica la percentuale di aggiornamento dei pesi (ad es. 0,001). Valori maggiori (ad es. 0,3) comportano un apprendimento iniziale più rapido prima che la frequenza venga aggiornata. Valori più piccoli (es. 1.0E-5) rallentano l’apprendimento durante l’allenamento
beta1: il tasso di decadimento esponenziale per le prime stime del momento (ad es. 0,9).
beta2: il tasso di decadimento esponenziale per le stime del secondo momento (ad es. 0,999). Questo valore dovrebbe essere impostato vicino a 1.0 su problemi con un gradiente scarso (ad es. NLP e problemi di Computer Vision).
epsilon: è un numero molto piccolo per evitare qualsiasi divisione per zero nell’implementazione.
Possiamo vedere che le popolari librerie di deep learning utilizzano generalmente i parametri predefiniti raccomandati:
TensorFlow : learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08.
Keras: lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decadimento=0.0.
Blocks: learning_rate=0.002, beta1=0.9, beta2=0.999, epsilon=1e-08, decay_factor=1.
Lasagne: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
Caffe: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
MxNet: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
Torch: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8

AUTORE:Data Masters Apri profilo LinkedIn
Data Masters è l’AI Academy italiana che offre percorsi di formazione nei settori della Data Science, del Machine Learning e dell’Intelligenza Artificiale. I nostri corsi di formazione sono progettati per applicare immediatamente l’Intelligenza Artificiale in ogni settore lavorativo e accompagnare aziende e professionisti in percorsi di upskilling e reskilling.











