
Se fino a ieri i riflettori erano puntati quasi esclusivamente sugli LLM come la famiglia GPT di OpenAI o Google Gemini, oggi un approccio differente, mutuato dal mondo della generazione di immagini, si sta facendo strada con prepotenza anche nel dominio del linguaggio.
L’idea di base è tanto elegante quanto potente: invece di generare testo una parola alla volta in sequenza, come fanno i modelli autoregressivi, i modelli diffusion lavorano in parallelo, perfezionando un’intera sequenza di testo partendo dal puro “rumore”. È un po’ come uno scultore che parte da un blocco di marmo informe e, togliendo il superfluo, fa emergere la statua che vi era nascosta.
Cosa sono i modelli Large Language Diffusion?
Per comprendere appieno l’essenza dei Large Language Diffusion Models, è utile fare un passo indietro e guardare al mondo da cui traggono ispirazione: quello della generazione di immagini.
Modelli come DALL-E, Midjourney e Stable Diffusion hanno abituato il grande pubblico ad immagini di una qualità e coerenza sorprendenti, generate a partire da semplici descrizioni testuali. Il motore che alimenta queste creazioni è proprio il “modello di diffusione”. In termini molto semplici, questi modelli imparano ad invertire un processo di “distruzione”. Durante l’addestramento, prendono un’immagine pulita e vi aggiungono gradualmente del rumore gaussiano, passo dopo passo, fino a trasformarla in una nuvola indistinta di pixel casuali. Successivamente, il modello viene addestrato a compiere il percorso inverso: partendo dal rumore puro, impara a rimuoverlo progressivamente per ricostruire un’immagine coerente ed attinente alla descrizione fornita.
Ora, proviamo a trasporre questo concetto dal dominio visivo a quello testuale. L’idea, apparentemente controintuitiva, è di fare la stessa cosa con le parole. Un LLDM parte da una sequenza di “token” casuali, una sorta di rumore linguistico senza senso, e attraverso una serie di passaggi iterativi di “denoising” (rimozione del rumore), li trasforma in una frase, un paragrafo o un intero documento di testo coerente, grammaticalmente corretto e semanticamente rilevante. A differenza dei tradizionali LLM, che operano in modo sequenziale prevedendo la parola successiva data la sequenza precedente (un processo chiamato “campionamento autoregressivo”), gli LLDM lavorano sull’intera sequenza simultaneamente. Questo approccio olistico e parallelo rappresenta la vera chiave di volta ed il principale elemento di differenziazione.
Potremmo pensare ai modelli autoregressivi come a un narratore che costruisce una storia una frase alla volta, senza sapere esattamente dove andrà a parare tra dieci pagine. Ogni nuova parola dipende strettamente da quelle che la precedono, il che può portare a problemi di coerenza a lungo raggio o a una certa “miopia” contestuale. Gli LLDM, invece, si comportano più come un redattore che ha davanti a sé una bozza completa, anche se inizialmente caotica e piena di errori (il nostro “rumore”), e la raffina iterativamente, sistemando la struttura, migliorando il flusso e assicurandosi che ogni parte sia in armonia col tutto. Questa capacità di considerare il contesto globale fin dall’inizio del processo generativo è ciò che li rende così promettenti e, per certi versi, più simili al modo in cui un essere umano scrive e revisiona un testo. Stiamo parlando di un cambiamento fondamentale nell’architettura e nella filosofia di addestramento dei modelli linguistici, un passaggio da una generazione sequenziale e locale ad una generazione parallela e globale.
Come funzionano i modelli Large Language Diffusion
Entrare nei dettagli del funzionamento dei Large Language Diffusion Models richiede di familiarizzare con alcuni concetti chiave, primo fra tutti quello di “spazio latente“. Nel machine learning, uno spazio latente è una rappresentazione compressa dei dati. Invece di lavorare direttamente con le parole (che sono entità discrete e complesse), i modelli spesso le trasformano in vettori numerici densi, noti come “embedding”. Questi vettori catturano le relazioni semantiche e sintattiche tra le parole in uno spazio matematico.
Il processo di diffusione negli LLDM avviene proprio in questo spazio latente. Si parte da una sequenza di embedding che rappresenta un testo pulito e coerente. A questo punto, inizia il “processo forward” (o di diffusione): ad ogni passo, una piccola quantità di rumore gaussiano viene aggiunta a questi embedding, corrompendoli gradualmente. Dopo un numero sufficiente di passaggi, la rappresentazione iniziale del testo diventa indistinguibile da un insieme di vettori casuali. Questa fase è cruciale per l’addestramento, perché insegna al modello la traiettoria che porta da un dato strutturato ad uno stato di caos completo.
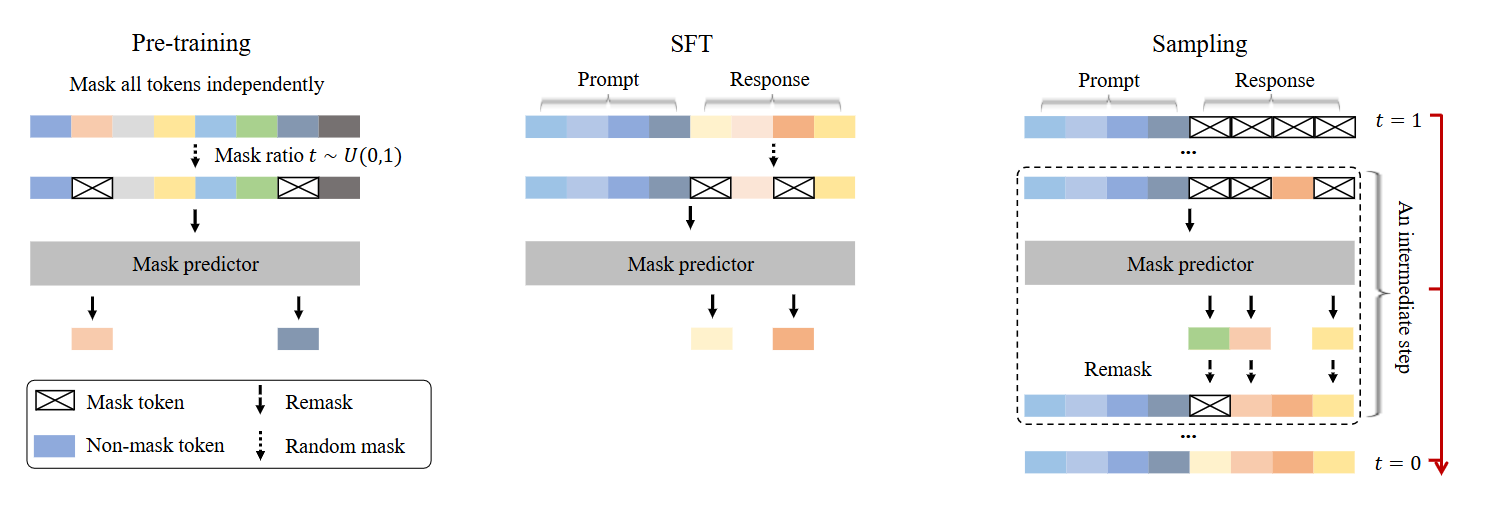
Fonte: https://ml-gsai.github.io/LLaDA-demo/
Il cuore del modello, però, è il “processo reverse” (o di denoising). Qui, il sistema impara a fare il percorso inverso. Partendo da puro rumore (vettori casuali nello spazio latente), il modello deve prevedere e rimuovere il rumore aggiunto in ogni passaggio per ricostruire, passo dopo passo, la sequenza di embedding originale. È un’operazione di raffinamento iterativo. Ad ogni step, il modello osserva lo stato attuale, leggermente “rumoroso”, e cerca di predirne una versione un po’ più “pulita”.
Ripetendo questo processo per decine o centinaia di volte, si arriva ad una rappresentazione finale che può essere riconvertita in testo leggibile. Per guidare questa ricostruzione verso un obiettivo specifico (ad esempio, per generare un testo che parli di un certo argomento), si introduce un “condizionamento”, che di solito è un embedding del prompt fornito dall’utente. Questo condizionamento agisce come una sorta di calamita, attirando il processo di denoising verso aree dello spazio latente che corrispondono a testi pertinenti alla richiesta.
Vantaggi rispetto ai tradizionali modelli linguistici
Il passaggio da un approccio autoregressivo ad uno basato sulla diffusione non è un mero esercizio di stile accademico, ma porta con sé una serie di vantaggi concreti che potrebbero risolvere alcune delle sfide più note nel campo della generazione del linguaggio naturale.
Uno dei principali punti di forza degli LLDM è la loro capacità di generare testo con una maggiore coerenza globale e diversità. I modelli autoregressivi, generando una parola alla volta, possono talvolta “dimenticare” il contesto iniziale in testi molto lunghi o cadere in cicli ripetitivi, un fenomeno noto come “degenerazione del testo”. L’approccio olistico degli LLDM, che raffina l’intera sequenza simultaneamente, mitiga questo problema. Avendo una visione d’insieme fin dal primo passo, il modello può garantire che l’inizio, la parte centrale e la fine di un documento siano tematicamente e stilisticamente allineati. Inoltre, la natura stocastica del processo di denoising introduce una variabilità più naturale nelle generazioni, consentendo di produrre una gamma più ampia di risposte plausibili per lo stesso prompt, senza sacrificare la qualità.
Un altro vantaggio significativo risiede nel controllo più granulare sul processo generativo. Poiché la generazione avviene attraverso una serie di piccoli passi di raffinamento, diventa teoricamente possibile intervenire in qualsiasi punto del processo. Si potrebbe, ad esempio, “guidare” la generazione a metà percorso per enfatizzare un certo concetto, modificare lo stile o correggere un errore senza dover ricominciare da capo. Questo apre le porte a tecniche di “inpainting” testuale (riempire parti mancanti di un testo) o “editing” guidato che sono molto più complesse da implementare in modo efficace con i modelli autoregressivi. Si potrebbe pensare di fornire una struttura di base di un documento con alcuni punti chiave e lasciare che il modello “diffonda” il resto del contenuto attorno a questi pilastri.
Infine, l’architettura non autoregressiva degli LLDM li rende intrinsecamente parallelizzabili. La generazione sequenziale parola per parola degli LLM tradizionali crea un collo di bottiglia computazionale. Ogni nuova parola può essere generata solo dopo che la precedente è stata determinata. Gli LLDM, invece, elaborano tutti i token della sequenza in parallelo ad ogni passo di denoising. Sebbene il processo richieda più passaggi iterativi, ogni singolo passo può essere eseguito in modo molto più efficiente sull’hardware moderno (come le GPU), portando potenzialmente ad una generazione più veloce, specialmente per testi di notevole lunghezza. Questo parallelismo non solo impatta la velocità di inferenza, ma semplifica anche l’architettura del modello, eliminando la necessità di meccanismi di mascheramento complessi tipici dei modelli Transformer autoregressivi.
A cosa servono i Large Language Diffusion Models
Sebbene la tecnologia dei Large Language Diffusion Models sia ancora in una fase relativamente nascente rispetto ai suoi cugini autoregressivi, le sue caratteristiche uniche aprono scenari applicativi estremamente interessanti, che vanno oltre la semplice generazione di testo lineare. La loro capacità di operare in modo olistico e controllabile li rende particolarmente adatti a compiti che richiedono una profonda comprensione strutturale e la capacità di manipolare il testo in modi non sequenziali.
Applicazioni pratiche dei LLDM
Una delle aree più promettenti è quella della scrittura assistita e della revisione di testi. Immaginiamo un editor di testo intelligente che non si limita a suggerire la parola successiva, ma che può prendere un paragrafo abbozzato e “raffinarlo” per migliorarne la coerenza, lo stile o la chiarezza. Un utente potrebbe scrivere una bozza grezza, evidenziare una sezione e chiedere al modello di “renderla più formale” o “aggiungere più dettagli tecnici”. L’LLDM potrebbe ricalcolare quella porzione di testo nel contesto dell’intero documento, garantendo transizioni fluide e mantenendo l’integrità del messaggio. Questo va ben oltre la correzione grammaticale e si avvicina ad una vera e propria collaborazione creativa tra uomo e macchina.
Un altro campo di applicazione è la generazione di testo strutturato. Compiti come la stesura di poesie con schemi di rime e metrica specifici, la generazione di codice con una struttura complessa o la creazione di sceneggiature che rispettino i formati standard sono notoriamente difficili per i modelli autoregressivi. Questi ultimi tendono a perdere di vista i vincoli a lungo raggio. Gli LLDM, grazie alla loro visione globale, potrebbero essere addestrati a rispettare queste strutture complesse. Si potrebbe fornire uno schema di un documento (ad esempio, introduzione, tre argomenti principali, conclusione) e lasciare che il modello “riempia” i contenuti, garantendo che ogni sezione sia sviluppata in modo appropriato e collegata logicamente alle altre.
L’inpainting testuale, o completamento di lacune, è un’altra applicazione naturale. Pensiamo a documenti storici danneggiati, a trascrizioni con parti mancanti o semplicemente ad un’email in cui vogliamo inserire una frase nel mezzo di un paragrafo. Gli LLDM possono prendere un testo con degli spazi vuoti (“masked tokens”) e ricostruire il contenuto mancante in modo che sia perfettamente coerente con ciò che lo precede e ciò che lo segue. Questa capacità di “guardare in entrambe le direzioni” è un vantaggio intrinseco rispetto ai modelli che possono solo guardare al passato.
Potenziale dei LLDM in vari settori
Le implicazioni di queste capacità si estendono a numerosi settori. Nel marketing e nella comunicazione, gli LLDM potrebbero generare campagne pubblicitarie altamente personalizzate, partendo da un template e adattando dinamicamente il tono, lo stile e il contenuto in base al profilo del destinatario. La capacità di revisionare e iterare rapidamente su diverse versioni di un copy potrebbe accelerare notevolmente i flussi di lavoro creativi.
Nel settore legale e finanziario, dove la precisione e la coerenza dei documenti sono fondamentali, questi modelli potrebbero essere utilizzati per redigere contratti, report e analisi, garantendo che tutte le clausole e le sezioni siano allineate e prive di contraddizioni. La loro abilità nel gestire testo strutturato li renderebbe ideali per compilare documenti complessi partendo da dati grezzi.
Nel campo della ricerca scientifica e accademica, un LLDM potrebbe assistere i ricercatori nella stesura di articoli, aiutando a strutturare il paper, a parafrasare sezioni per migliorarne la leggibilità e persino a generare bozze di abstract o conclusioni basate sul corpo del testo. Questo potrebbe democratizzare l’accesso alla pubblicazione scientifica, aiutando i ricercatori non madrelingua a produrre testi di alta qualità.
Anche il mondo dell’intrattenimento e dei media potrebbe beneficiare enormemente da questa tecnologia. Scrittori e sceneggiatori potrebbero usarli come partner di brainstorming, generando rapidamente trame alternative, dialoghi o descrizioni di scene. Nel giornalismo, potrebbero aiutare a riassumere eventi complessi da più fonti, creando narrazioni coerenti e ben strutturate.
I consigli di Data Masters su come rimanere aggiornati
Il campo dell’intelligenza artificiale generativa si muove a una velocità vertiginosa. Quello che oggi è considerato lo stato dell’arte, domani potrebbe essere già superato da un nuovo paper o da un modello open source rilasciato durante la notte. Per chi lavora con i dati e vuole rimanere competitivo e rilevante, l’aggiornamento costante non è un’opzione, ma una necessità. L’avvento dei Large Language Diffusion Models è l’ennesima dimostrazione di quanto sia cruciale mantenere un atteggiamento di curiosità ed apprendimento continuo.
Il primo passo, e forse il più importante, è non farsi intimidire dalla complessità. Concetti come “spazio latente”, “processo di denoising” o “architetture non autoregressive” possono sembrare ostici, ma la chiave è approcciarli un passo alla volta. Un ottimo punto di partenza è seguire le fonti giuste. Dedicate una parte della vostra settimana alla lettura di blog specialistici, alla visione di video divulgativi di canali accreditati e, per i più audaci, a dare uno sguardo ai paper originali pubblicati su piattaforme come arXiv. Spesso, gli autori stessi o la community di ricerca forniscono spiegazioni e sintesi che rendono accessibili anche i concetti più complessi.
Un altro consiglio fondamentale è quello di “sporcarsi le mani”. La teoria è importante, ma la vera comprensione arriva con la pratica. Non appena saranno disponibili modelli LLDM open source accessibili o API per sperimentare, non esitate a provarli. Confrontate i loro output con quelli di modelli più tradizionali come GPT o Llama. Provate a dar loro in pasto prompt che mettano in difficoltà i modelli autoregressivi, come richieste di testi con strutture complesse o compiti di editing. Questa sperimentazione diretta vi darà un’intuizione pratica dei loro punti di forza e di debolezza che nessun articolo potrà mai sostituire.
Infine, investire nella propria formazione è sempre una scelta vincente. Se siete interessati a capire come orchestrare modelli linguistici complessi per creare applicazioni potenti, potreste trovare utile un corso per sviluppare Agenti AI, che fornisce le basi per costruire sistemi intelligenti capaci di risolvere problemi complessi.
L’arrivo dei Large Language Diffusion Models ci ricorda che il viaggio nel mondo dell’intelligenza artificiale è una maratona, non uno sprint. La curiosità, la sperimentazione e la formazione continua sono la bussola e la mappa che ci permetteranno di navigare con successo le sfide e le opportunità di questo campo in perenne evoluzione. Il futuro non aspetta, e per chi si occupa di dati, essere pronti a capirlo e a modellarlo è il nostro compito più importante.

AUTORE:Simone Truglia Apri profilo LinkedIn
Simone è un Ingegnere Informatico con specializzazione nei sistemi automatici e con una grande passione per la matematica, la programmazione e l’intelligenza artificiale. Ha lavorato con diverse aziende europee, aiutandole ad acquisire e ad estrarre il massimo valore dai principali dati a loro disposizione.











